Jimmy Talk
Jimmy Talk【论文泛读】PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding

目录
泛读腾讯 ARC Lab 与南开大学程明明老师联合发表的PhotoMaker论文,大致介绍动机、实现方法与成果
动机
DreamBooth 痛点
- 定制时间慢:由于需要在“测试”(定制)阶段对模型进行微调,理论上消耗的时间往往需要大约 15 分钟,在一些商业化的 APP 上,由于资源分配和排队的问题这一定制时间甚至要更久(数小时到数天)。
- 消耗显存高:如果不进行额外的优化,在 SDXL 底模上执行定制化过程只能在专业级显卡上进行,这些专业级显卡的昂贵都是出了名的。
- 对输入素材要求高:以妙鸭举例,它要求用户输入 20 张以上高质量的人像照片,且每次定制过程都需要重新进行收集。对用户来说非常不友好。
Insight
先前的工作都局限于下列两点:
- 输入图像和输出图像都来源于同一张图片,即得到的 embedding 很容易学习到姿态、表情这些与身份 ID 不相关的属性。
- 输入的每个 ID 图像都表征为了单一的 embedding。缺乏一定的可编辑性与变化,很难改变人脸相关的属性。
Target
- high efficiency: 高性能、低耗时的生成 AI 图像
- promising identity (ID) fidelity: 高度保真的身份 ID
- flexible text controllability: 灵活可靠的控制能力,主要体现在文本参数
实现方法
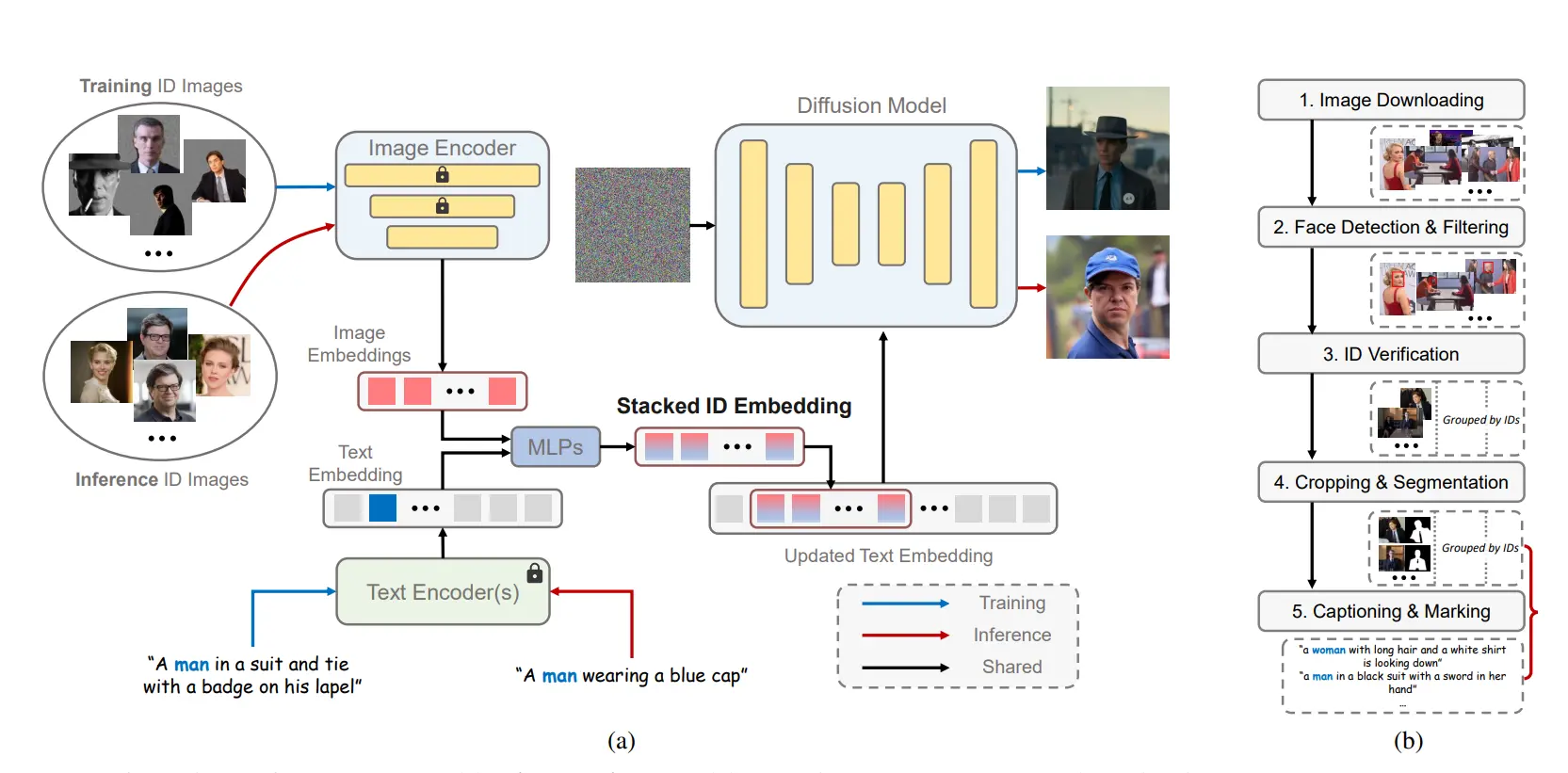
解决方案
- 训练时,对于输入图像和输出的目标图像不来源与同一个图像。
- 送入多个同一身份 ID 的图像,提取 embedding 以输出一个全面而统一的表达,称为 Stacked ID embedding。
Stacked ID embedding 中存取的每个 embedding 它们的图像来源可能姿态不同,表情不同以及配饰不同,但 ID 都是相同的,因此可以隐式的将 ID 与其他与 ID 无关的信息解耦,以使其只表征待输出的 ID 信息。
训练流程
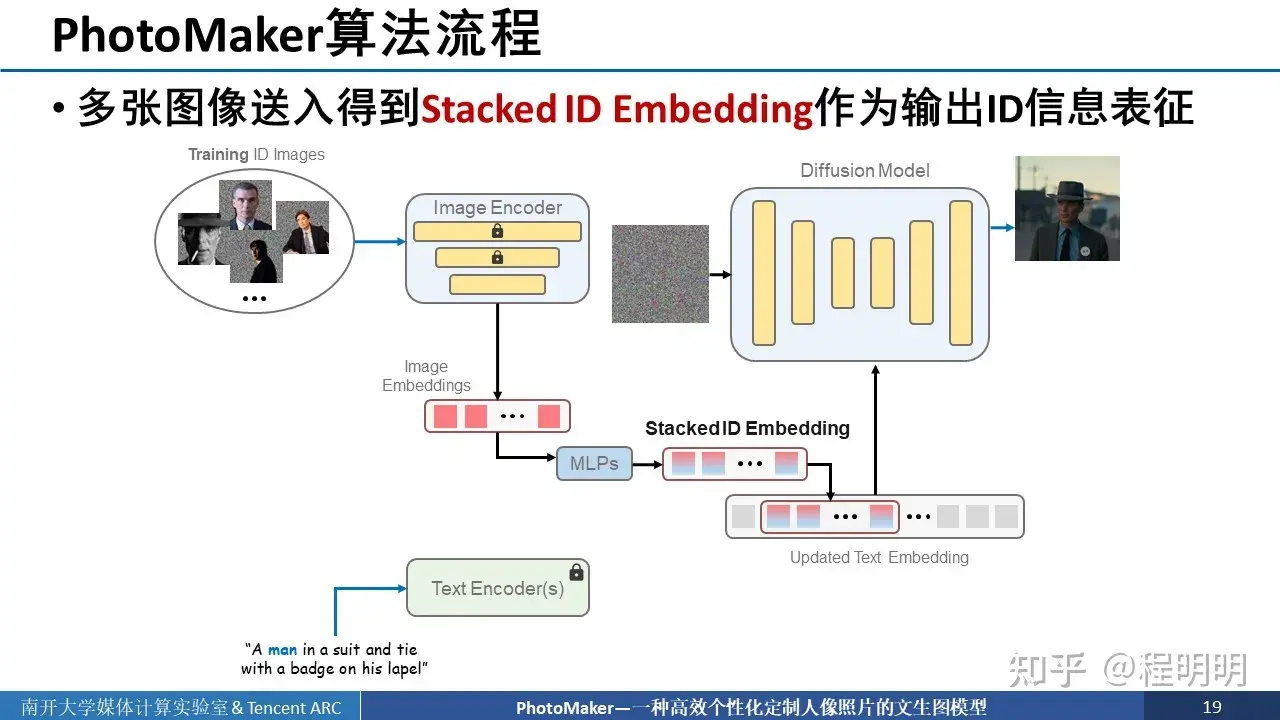
- 把同一 ID 的多个图像送入图像编码器进行编码,得到多个 Image Embedding;
- 对下方输入的文本进行 Encode 得到 Text Embedding,并且找出触发词,如图中输入的man。
- 使用 MLP 对 Text Embedding 和 Image Embedding 进行混合得到 Stacked ID Embedding,即 Text Embedding 与每个 Image Embedding 进行混合
- 将得到的 Stacked ID Embedding 与 Text Embedding 中对应位触发词位置的 Embedding 进行替换,进而得到更新后的 Text Embedding。
- 将更新后的 Text Embedding 放入 Diffusion Model 中,通过 Cross Attention 层进行融合。此外,还在每一个注意力层中添加了 LoRA 模块进行更新。
训练细节
训练时,并不训练 Diffusion Model 的原始参数,而是对每个 Cross 训练 LoRA,这样子既可以保留原始 Diffusion Model 的 Performance,也可以避免训练时大参数的时间消耗,并且 LoRA 可以有助于保存当前人脸身份。不仅微调的参数量变少了、消耗的资源更少了、速度变快了,还可以达到比 DreamBooth 更好的效果。
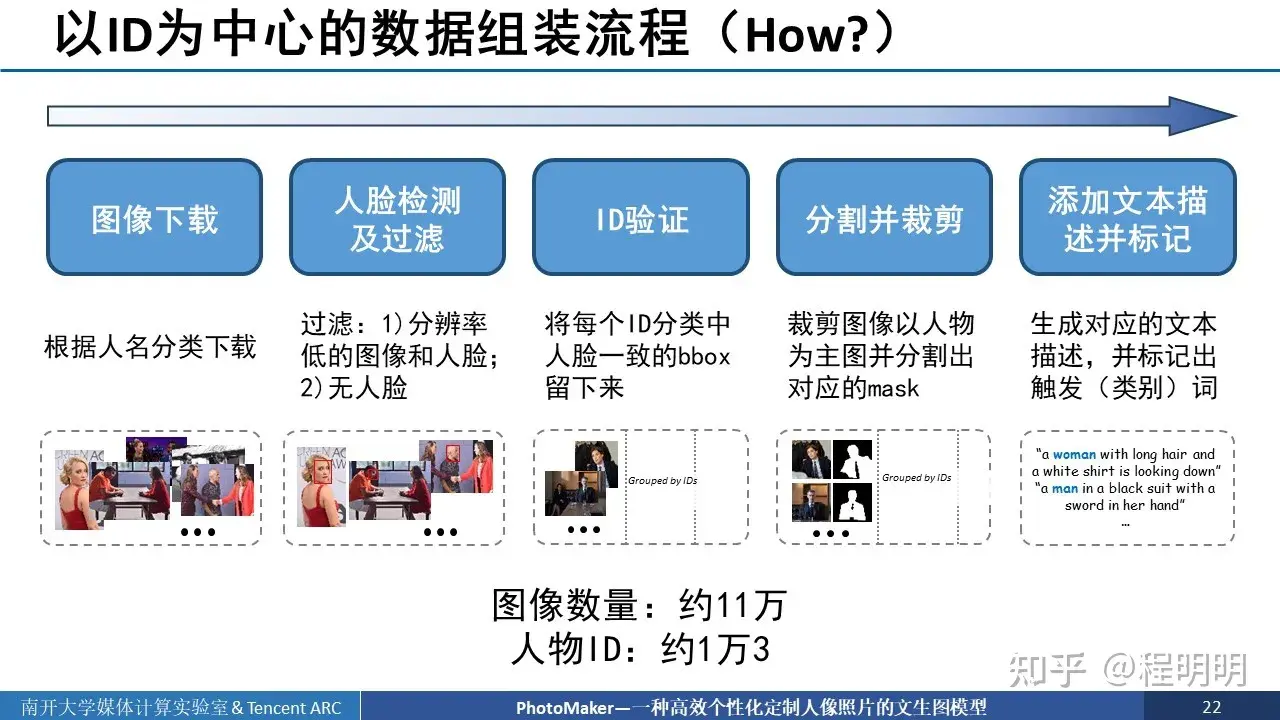
数据集
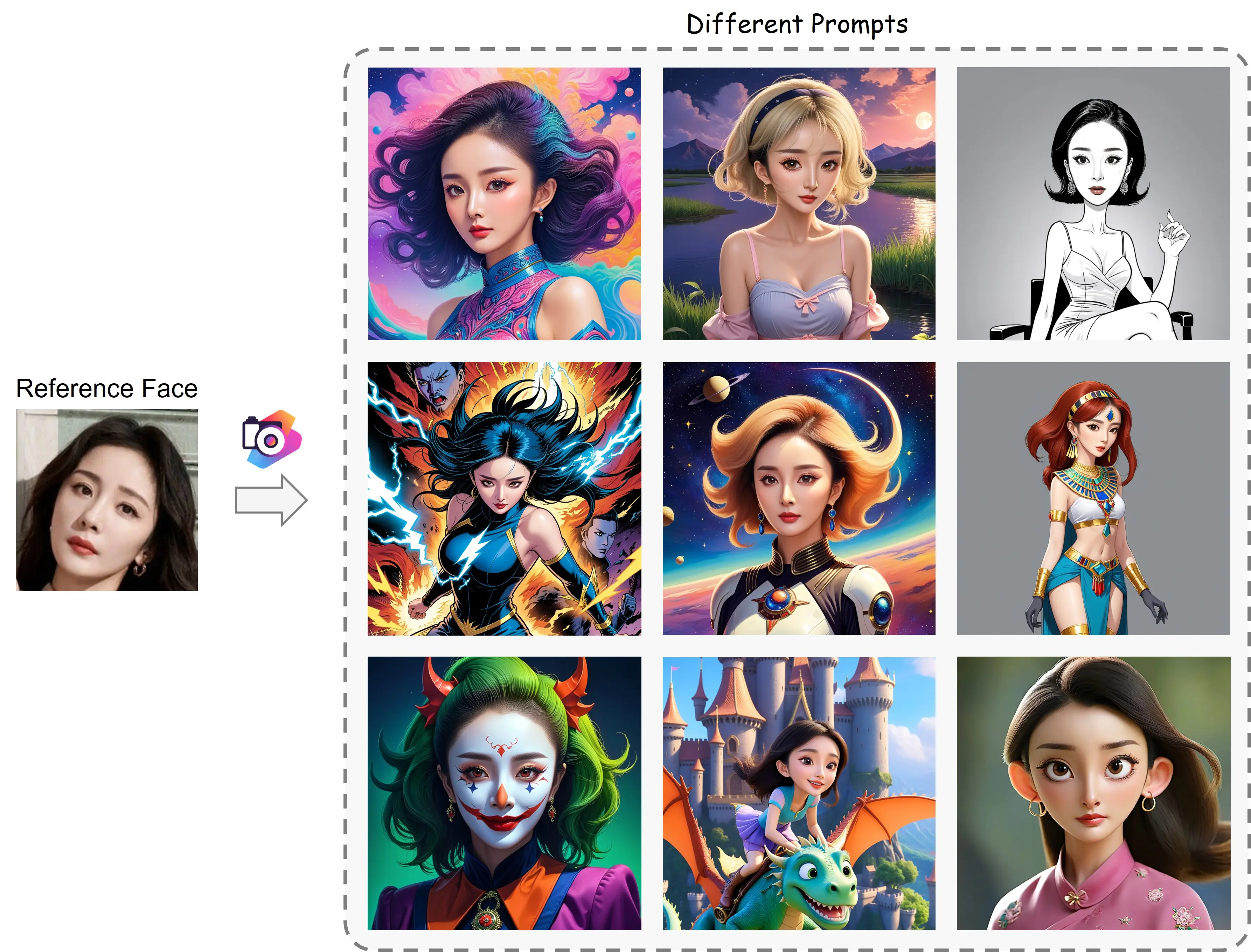
结果
Realistic

Stylization